As i understood, some things depend on the location type code (like if it can hold actual items, if it can be parent or child of other location etc) and other things depend on extra options governed by activities. NB: it seems to be logical to move ALL this logic to be activity based probably?
There are more Location Type Codes than described in the documentation, what are they for?
CONSUMER
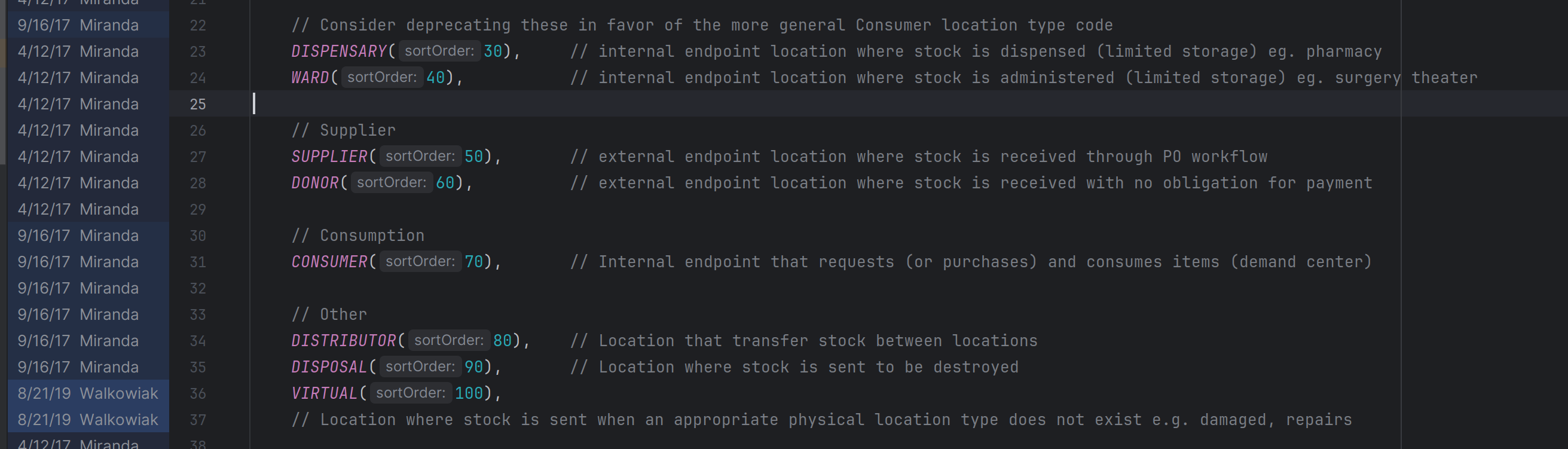
DISPOSAL
What is actually the difference between WARD and DISPENSARY?
What is the difference between BIN_LOCATION and INTERNAL?
Now for activities
dynamic creation - i suppose this is what enables the buttons like “add destination” on the Outbound shipment form etc?
allow over-pick
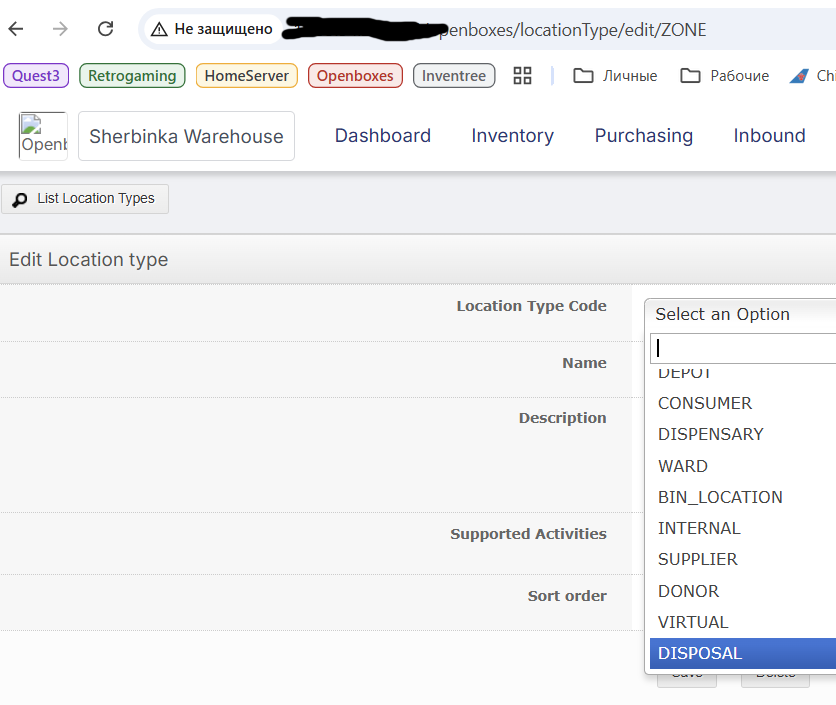
And while exploring all this stuff i managed to damage the data in some way - i would consider this as a bug:
i have noticed that while editing default Zone (Location type which comes “out of the box”) it`s Location type code in the upper box was not set to ZONE, but was set to “select an option”. After clicking Save Location Type code was actually cleared and what is more interesting i can not get it back since there is no ZONE Location Type Code in the list.
A this point it is not possible to add or see zones for depots, in Bin locations tab zones created earlier are displayed for the bins, but Zone locations tab is empty etc.
I’m not sure about all of these but will answer what I know:
I have never used any other location type code, but my assumption is that these additional codes have the exact same functionality and activity codes as WARD. Likely they were added to be descriptive of what the location is but they do not work differently from other destination locations
Similar to above, WARD and DISPENSARY have no functional difference. Two location types exist if the user wanted to easily distinguish their wards from their dispensaries in a list or in custom reporting/documents. Personally, I use WARD for every single destination location regardless of what it actually is. However, I did work on an implementation where they needed to generate custom shipping documentation depending on the type of location they were sending to, and then I used the location types as a reference for the custom documentation
INTERNAL locations are bin locations that have special behaviors built into the code, not dictated by supported activities. Receiving bins, Hold bins, and Cross-docking (which does not actually have any functionality but was added with the intention of building that eventually) are INTERNAL. If you want to create a custom location/location type, I would strongly suggest using BIN_LOCATION as INTERNAL is not designed to be used for custom location types (although the system probably allows it)
Activities:
Dynamic creation - you are exactly right. Put it on a location type to allow the user to create a new location of that type within the outbound movement workflow. Shouldn’t be added directly to location supported activities as it wont do anything - only on the location type
allow-over-pick - I have never seen this one before, and am not sure what it would do as the system already allows manual over-pick. Maybe it’s available in some versions not others
Probably you could give some advise based on your experience: what we do is servicing different hardware and for that matter we use field technicians.
We need to keep track of the parts:
1 which have been diven to them from depot for particular repair under some ticket (with the reference to this ticket)
2 which have been given them for their mobile in-car depot
3 which of the above parts they have eventually used for the customer repairs
3.1 parts used for the repairs need to be tracked and somehow “confirmed/completed” after some external administrative activities have been performed.
3.2 repairs may result in customer`s defective part being returned - it should be tracked and in some cases returned to the external party (producer).
Technician should be able to request the part from depot (but not “take” it by himself) and confirm the reception once the part has been provided.
He should be able to initiate return of the unused part to the depot.
PS: and what is important - somehow we must track the state of the part (it could be dead on arrival, damaged etc so it will requre further processing). I have not found any “status” of the stock items yet, probably i must go deeper into openboxes documentation.
I would be very grateful if you could share some thoughts on to what extent this is achievable within openboxes?
Yes, this is most certainly a bug. We’ll create a ticket for it. If you haven’t run that reset, I can provide the SQL statement to fix the zone location type.
NOTE: Since you’re just getting started, let me know if you would like to start with the most recent version (v0.9.3) of OpenBoxes instead of v0.8.x.
There are more Location Type Codes than described in the documentation, what are they for?
CONSUMER
DISPOSAL
We wanted the user to be able to define consumption endpoints that provided more nuance than just “location where stock was consumed”. The idea was that we could use the different consumer endpoints to understand how stock is being consumed by the supply chain system (wasted, consumed, damaged, shrinkaged). We have the same concept at the Transaction Type level (i.e. each transaction to an endpoint can include this type of classification) so you can decide which method makes more sense to track that metadata.
What is actually the difference between WARD and DISPENSARY?
This is another example of the “nuanced” location type. A WARD represents an in-patient hospital ward where stock would likely be stored in a closet or cabinet and consumed via an administration event. The DISPENSARY might represent an out-patient pharmacy within a hospital or independent of the hospital system. Sending stock to either of these locations has the same effect on the warehouse that is fulfilling the request (i.e. stock is effectively consumed), but the location type provides metadata about what is consuming the stock which might be used to understand the events that might occur at those locations (dispensed 30 pills to patient, administered one dose every day for a week). Whether that distinction is important to you depends on your use cases.
The following FHIR documentation provide a bit more context for the events that might occur within the consumer location.
There’s a good chance you don’t need to make a distinction between your consumer location types, in which case CONSUMER probably makes the most sense. There’s also a good chance that we don’t have a location type code that best represents your particular use case (for example we might not include the concept of a STORE where POS transactions occur). So just let us know and we can add them.
Aside: One underlying assumption that should be discussed is that OpenBoxes is not designed to track the transactions that occur at a consumer endpoint (i.e. point of sale / point of service). Those use cases would need to be supported by other systems like a POS terminal and potentially communicated back to OpenBoxes or a separate reporting system like DHIS2.
Having the data from both systems (WMS and POS) would allow us to reconcile the consumed signal from the warehouse (sum of all outbound transfers to consumer) with the consumed signal from the consumer (sum of all dispensing/shrinkage transactions to actual consumer i.e. patients) so that we could calculate and understand the efficiency of the entire supply chain. At the moment, a warehouse that sends 1000 EA of Ibuprofen tablets to a consumer endpoint ASSUMES that all stock is being dispensed to patients efficiently. However, what is happening inside the pharmacy might tell us a completely different story (820 EA dispensed, 80 damaged/disposed, 100 EA expired).
Reconciling these stories is an important part of effective supply chain analysis. And eventually I would like to bridge that gap by integrating systems (OpenBoxes, OpenMRS, dispensing systems, POS) together using OpenHIE and creating a reporting layer using DHIS2 to communicate and marry the different signals being emitted by each system. The same type of integration should be possible with non-healthcare use cases like retail/sales.
What is the difference between BIN_LOCATION and INTERNAL?
BIN_LOCATION was added first and represents internal locations that serve as bin locations within a warehouse racking system i.e. pickface, reserve racking, etc. INTERNAL was added to represent internal locations where stock might be stored temporarily before being putaway or shipped i.e. dock doors, staging, receiving, hold locations for returns, etc.
They are essentially the same with some nuance. I realized after adding BIN_LOCATION that it would have been better to create a single location type code (i.e. INTERNAL) to represent all internal locations of a warehouse and to allow the supported activities to distinguish between them i.e. a picking location would use PICK_STOCK/PUTAWAY_STOCK, a receiving location would use RECEIVE_STOCK, hold locations whether bin locations or staging areas for returns would use HOLD_STOCK.
For the most part that is how the system should work, and is working. But there might be places where that refactoring hasn’t occurred we’re still pulling just locations with location_type_code = BIN_LOCATION, instead of location_type_code IN (BIN_LOCATION, INTERNAL).
VIRTUAL is used as a way to record transactions to “virtual” states that might not have a physical location (e.g. Borrowed, In Repair, Deployed, Scrapped, Flushed, Destroyed, Incinerated, Stolen).
Let’s take Incinerated as an example. The concept of “stock has been incinerated” could be implemented in multiple ways within OpenBoxes:
Transfer to Physical Location destination (Incinerator) on the premises
Transfer to Virtual Location destination as a state (Incinerated)
Transfer to Blackhole destination with Transaction Type = Incinerated
Consumption transaction (no destination) with Transaction Type = Incinerated
And you could even add internal locations to store stock ahead of it being incinerated.
Internal Location (Ready to Incinerate)
So this is one of those cases where you would need to decide which approach makes most sense for your implementation.
There are a number of ways to do this within OpenBoxes, but it’s not going to be streamlined to your wofklows. In fact, this is going to require heavy data entry. Whether OpenBoxes is suitable, depends on an analysis on the use case breakdown between consumption of parts/goods and tracking of assets. If you’re more interested in the deployment/usage of parts and tools, then I might recommend an asset tracking systems like snipeitapp.com (asset tracking of IT equipment devices) or even a more general ERP with asset tracking feature or module like Odoo and ERPNext. Or the system you have in your saved links from the screenshot (inventree.org).
Technician should be able to request the part from depot (but not “take” it by himself) and confirm the reception once the part has been provided. He should be able to initiate return of the unused part to the depot.
I could also see a case where you could you use the OpenBoxes API, but build a separate UI to handle the workflows that you’re describing. This would allow you to build streamlined workflows for each of the use cases you’re describing. If you don’t have any developers but you do have a budget for development, we could work with you on a project to build an application to handle these workflows.
I have performed the reset already, but probably posting the SQL statement to recover from such an issue would be nice if anyone else encounters this issue.
i`m on release/0.9.2 currently, is this not the latest version?
Frankly speaking i have not looked into Transaction types yet and quck search in the Administration guide gave me zero results
Sure, but what is the actual difference between being transferred to the VIRTUAL location and to any other “consuming” location be it CUSTOMER, DISPOSAL, WARD or DISPENSARY? I mean, besides that you could later get some analytics based on the location type is there any technical difference between those options baked into the program logic?
Sorry for asking, but i would like to understand their intended role/usage to make the right choice - probably additional functionality is planned to be implemented at a later point.
At this point it looks like combination of only CUSTOMER for real consumption and VIRTUAL for anything else would make most sense for us.
so for now it is better to use BIN_LOCATION for any custom bin types, got it.
Inventree - Imported data for one of our depots, our part catalogue. They have very simple add/remove stock item process, min/max/reorder levels and related replenishment reporting/process is very basic (we have print service projects where consumption statistics, planning are critical because of greater parts/consumables usage rates than general server hardware support).
Nice features are serialization and stock item statuses (which impact “availability” of the said item), possibility to nest locations indefenitely with the ability to customize which of them may hold items and which are purely “structural”, same goes for part categories - you may customize which are just for grouping and which are assignable to the parts. They have extensive API and use python which is far more usual than grails nowadays
General simplicity is a downside aswell - outside of purchasing and sales process there is amost no concept of the “document” as envelope for the item movements. Transfers between depots are one-stage process, there is no picking etc. Has emphasis on the build/manufacturing process.
Odoo and Dolibarr - well… i have briefly tested both of them. They are big, but doing a lot more than warehouse management they do it less deep in most aspects and/or require significat amount of side activities like actvating “shipments” activates “sales orders” etc and all it grows like a snowball. And they still lack most specifics openboxes/inventree have.
I have even touched Tryton but got frustrated by its UI/UX and fled in terror.
We use SAP R/3 as our main system so “we have ERP system at home, son”
SnipeIt - that was the second one i have tried, as expected and declared by creators it is mostly cmdb/it support tool, it has almost nothing for proper warehouse management. Is seems to be more or less the same as GLPI (which one of our regional departments was using for their local activities)
I would like to avoid building new frontend (which could be possible both with openboxes and inventree). We have no such luxury unfortunately - so i have to try to squeeze our processes into the frames provided by the existing apps. At least for now.
My response(s) turned out to be longer than expected so let me know if I missed any of your questions.
i`m on release/0.9.2 currently, is this not the latest version?
Awesome. And sorry, the 0.9.3 release is imminent, so yes, you’re on the latest unofficially official stable release. We did release a somewhat unconventional “hotfix with new features” version (v0.9.2.2) that includes some improvements to Invoicing (better support for partial invoicing) and Outbound (full outbound import). But I would recommend waiting until 0.9.3 is released.
Frankly speaking i have not looked into Transaction types yet and quck search in the Administration guide gave me zero results
Transaction Types allow you to be more specific about why, where and how stock was consumed or produced. However, I just realized that creating custom Transaction Types might not be helpful as I initially thought. There’s not much (any) documentation around managing them because using custom transaction types would almost certainly require a developer to be involved.
For example, there’s currently no way to configure custom transaction types to replace system transaction types for existing features (external transfers like Stock Movements use the Transfer Out transaction type, expiry transactions use the Expired transaction type, etc). So, in order to take advantage of the custom transaction types, one of the following would need to happen:
You would need to create transactions with custom transaction types through the API
You would need to create transactions with custom transaction types through the generic credit / debit feature available from the product stock card. Note: This feature is not well-documented as I don’t think it’s used by the organization responsible for creating the Help docs i.e. Partners In Health.
Lastly, we could develop a feature to provide a configuration mechanism to set up different transaction types for each feature. The happy case for this is not difficult, but it probably won’t happen unless there’s significant interest since it will require some additional validation around edge cases to ensure the custom transaction type doesn’t break the feature.
I mean, besides that you could later get some analytics based on the location type is there any technical difference between those options baked into the program logic?
Not that I’m aware of. If there is, it’s legacy functionality that we should have replaced. The distinction between locations and location types is currently driven by the inheritable Supported Activities. In other words, Supported Activities are responsible for encoding logic into each facility-level and internal location. And as you saw earlier, Location Groups are involved with that as well, but the main driver is Supported Activities.
At this point it looks like combination of only CUSTOMER for real consumption and VIRTUAL for anything else would make most sense for us.
Yes, I would use the more generic CONSUMER and VIRTUAL location type codes for all outbound location types and states. And you could even consider removing Location Types that don’t fit your requirements.
In a comment added to the code way back in 2017, I mentioned that we should consider deprecating DISPENSARY and WARD since there’s no distinction between them and the CONSUMER location type code. They were introduced way at the beginning before Support Activities.
Admitting I haven’t fully read all of the above, but here is my take on what I would do if I had to set this up in OB with no dev support. Agree with Justin OB is not optimized for this use case, but I think you can get some of the way there with config and workarounds.
Tracking of part usage:
Each technician owns a depot location named after them. They create e-requests to the central depot.
Identification of reason for the request (mobile depot, repair, repair #) must be in name of request. Fulfilling user would need to be trained to reject requests not names properly
Fulfilling depot “ships” request when they hand it to technician; technician receives request into their depot
When a part is used in a repair, technician creates an outbound referencing the repair #. Destination location would be something generic, like “Technician name repairs.” You could also make each client a destination, depends on if you have a standard list of facilities/items you are repairing or if its extremely varied. If standard list, use individual destinations. If not, use name with generic destination.
- another option here is transfer stock, but it is an old feature and isnt fully working. Could be a small customization to get it working, but it also doesn’t have a comment. But its a much easier workflow that outbound.
Technician uses inbound return feature to receive defective parts from client. They can then ship those to central depot or to vendor using outbound return feature
Tracking the state of the part
This one is really tough because item status functionality straight up doesn’t exist in OB. BUT depending on how you need to use the status information, you may be able to use one of these workarounds.
Bin locations: This only works if an item is in inventory in a given location. It wont work if you need to status to follow the item to multiple locations. You could set up a bin for each status, and use putaway/transfer stock functionality to move items between statuses (bins). Damaged or similar bins can be marked as hold so you can see that stock is unusable.
Lot #: This is tricky and would need to be tested, but you could put the status in the lot. So the part is “Filter” and the lot is “damaged.” When you update the status, what you are essentially doing is an inventory updates to say, “Filter lot damaged now =0, Filter lot Refurbished now = 100”. You cannot use the edit lot functionality for this, because that will just change ALL damaged filters to new, instead of the one damaged filter. But this will carry through every workflow
All in all, you probably can fulfill your use case with OpenBoxes, but your technicians might riot . Its a lot of data entry for someone whose job is not managing a warehouse. I would look into Computerized Maintenance Management Systems rather than inventory systems maybe. I reviewed Upkeep and eMaint for work and it seemed like they would fit this use case (neither is open source unfortunately, but maybe there is an Open Source CMMS you could look into.)
I greatly appreciate your efforts invested into providing such a detailed reply. Some of the workarounds you have proposed came to my mind already.
Probably you are right and proper EAM/CMMS system would suit better, but after some research i came to conclusion that there are actually almost no opensource systems of this kind (we search for on-premise deployment as well), OpenMaint probably being one of the few. Quick search on GitHub yielded only abandonment
Actually, there are features present in systems like Inventree/Openboxes, which are at first glance missing in bigger systems like OpenMaint (at least that was my experience from shuffling through web demo) - they focus much more on the actual maintenance activities (preventive/corrective, SLAs etc), but lack in terms of inventory control.
We have ticket system which covers most of the CMDB/ticket activities, what we are looking for is a solution for operational inventory control (which we could connect with our ticket system via Rest API at some point).